2. Static Program Analysis for Security
Abstract
In this chapter, we discuss static analysis of the security of a system. First, we give a brief background on what types of static analysis are feasible in principle and then move on to what is practical. We next discuss static analysis of buffer overflow and mobile code, followed by access control. Finally, we discuss static analysis of information flow expressed in a language that has been annotated with flow policies.
2.1 Introduction
Analyzing a program for security holes is an important part of the current computing landscape, as security has not been an essential ingredient in a program's design for quite some time. With the critical importance of a secure program becoming clearer in the recent past, designs based on explicit security policies are likely to gain prominence.
Static analysis of a program is one technique to detect security holes. Compared to monitoring an execution at runtime (which may not have the required coverage), a static analysis -- even if incomplete because of loss of precision -- potentially gives an analysis on all runs possible instead of just the ones seen so far.
However, security analysis of an arbitrary program is extremely hard. First, what security means is often unspecified or underspecified. The definition is either too strict and cannot cope with the "commonsense" requirement or too broad and not useful. For example, one definition of security involves the notion of "noninterference" [24]. If it is very strict, even cryptoanalytically strong encryption and decryption does not qualify as secure, as there is information flow from encrypted text to plain text [59]. If it is not very strict, by definition, some flows are not captured that are important in some context for achieving security and hence, again, not secure. For example, if electromagnetic emissions are not taken into account, the key may be easily compromised [50]. A model of what security means is needed, and this is by no means an easy task [8]. Schneider [28] has a very general definition: a security policy defines a binary partition of all (computable) sets of executions -- those that satisfy and those that do not. This is general enough to cover access control policies (a program's behavior on an arbitrary individual execution for an arbitrary finite period), availability policies (behavior on an arbitrary individual execution over an infinite period), and information flow (behavior in terms of the set of all executions).
Second, the diagonalization trick is possible, and many analyses are undecidable. For example, there are undecidable results with respect to viruses and malicious logic [16]: it is undecidable whether an arbitrary program contains a computer virus. Similarly, viruses exist for which no error-free detection algorithm exists.
Recently, there have been some interesting results on computability classes for enforcement mechanisms [28] with respect to execution monitors, program rewriting, and static analysis. Execution monitors intervene whenever execution of an untrusted program is about to violate the security policy being enforced. They are typically used in operating systems using structures such as access control lists or used when executing interpreted languages by runtime type checking. It is possible to rewrite a binary so that every access to memory goes through a monitor. While this can introduce overhead, optimization techniques can be used to reduce the overhead. In many cases, the test can be determined to be not necessary and removed by static analysis. For example, if a reference to a memory address has already been checked, it may not be necessary for a later occurrence.
Program rewriting modifies the untrusted program before execution to make it incapable of violating the security policy. An execution monitor can be viewed as a special case of program rewriting, but Hamlen et al. [28] point out certain subtle cases. Consider a security policy that makes halting a program illegal; an execution monitor cannot enforce this policy by halting, as this would be illegal! There are also classes of policies in certain models of execution monitors that cannot be enforced by any program rewriter.
As is to be expected, the class of statically enforceable policies is the class of recursively decidable properties of programs (class of the arithmetic hierarchy): a static analysis has to be necessarily total (i.e., terminate) and return safe or unsafe. If precise analysis is not possible, we can relax the requirement by being conservative in what it returns (i.e., tolerate false positives). Execution monitors are the class of co-recursively enumerable languages (class of the arithmetic hierarchy).1
A security policy is co-recursively enumerable if there exists a Turing machine that takes an arbitrary execution monitor as an input and rejects it in finite time if ; otherwise loops forever.
A system's security is specified by its security policy (such as access control or information flow model) and implemented by mechanisms such as physical separation or cryptography.2 Consider access control. An access control system guards access to resources, whereas an information flow model classifies information to prevent disclosure. Access control is a component of security policy, while cryptography is one technical mechanism to effect the security policy. Systems have employed basic access control since timesharing systems began (1960) (e.g., Multics, Unix). Simple access control models for such "stand-alone" machines assumed the universe of users known, resulting in the scale of the model being "small." A set of access control moves can unintentionally leak a right (i.e., give access when it should not). If it is possible to analyze the system and ensure that such a result is not possible, the system can be said to be secure, but theoretical models inspired by these systems (the most well known being the Harrison, Ruzzo, Ullman [HRU] model) showed "surprising" undecidability results [29], chiefly resulting from the unlimited number of subjects and objects possible. Technically, in this model, it is undecidable whether a given state of a given protection system is safe for a given generic right. However, the need for automated analysis of policies was small in the past, as the scale of the systems was small.
While cryptography has rightfully been a significant component in the design of large-scale systems, its relation to security policy, especially its complementarity, has not often been brought out in full. “If you think cryptography is the solution to your problem, you don’t know what your problem is” (Roger Needham).
Information flow analysis, in contrast to access control, concerns itself with the downstream use of information once obtained after proper access control. Carelessness in not ensuring proper flow models has resulted recently in the encryption system in HD-DVD and BluRay disks to be compromised (the key protecting movie content is available in memory).3
The compromise of the security system DeCSS in DVDs was due to cryptanalysis, but in the case of HD-DVD it was simply improper information flow.
Overt models of information flow specify the policy concerning how data should be used explicitly, whereas covert models use "signalling" of information through "covert" channels such as timing, electromagnetic emissions, and so on. Note that the security weakness in the recent HD-DVD case is due to improper overt information flow. Research on some overt models of information flow such as Bell and LaPadula's [6] was initiated in the 1960s, inspired by the classification of secrets in the military. Since operating systems are the inspiration for work in this area, models of secure operating systems were developed such as C2 and B2 [57]. Work on covert information flow progressed in the 1970s. However, the work on covert models of information flow in proprietary operating systems (e.g., DG-UNIX) was expensive and too late, so late that it could not be used on the by then obsolescent hardware. Showing that Trojan horses did not use covert channels to compromise information was found to be "ultimately unachievable" [27].
Currently, there is a considerable interest in studying overt models of information flow, as the extensive use of distributed systems and recent work with widely available operating systems such as SELinux and OpenSolaris have expanded the scope of research. The scale of the model has become "large," with the need for automated analysis of policies being high.
Access control and information flow policies can both be statically analyzed, with varying effectiveness depending on the problem. Abstract interpretation, slicing, and many other compiler techniques can also be used in conjunction. Most of the static analyses induce a constraint system that needs to be solved to see if security is violated. For example, in one buffer overflow analysis [23], if there is a solution to a constraint system, then there is an attack. In another analysis in language-based security, nonexistence of a solution to the constraints is an indication of a possible leak of information.
However, static analysis is not possible in many cases [43] and has not yet been used on large pieces of software. Hence, exhaustive checking using model checking [14] is increasingly being used when one wants to gain confidence about a piece of code. In this chapter, we consider model checking as a form of static analysis. We will discuss access control on the Internet that uses model checking (Section 2.4.4). We will also discuss this approach in the context of Security-Enhanced Linux (SELinux) where we check if a large application has been given only sufficient rights to get its job done [31].
In spite of the many difficulties in analyzing the security of a system, policy frameworks such as access control and information flow analysis and mechanisms such as cryptography have been used to make systems "secure." However, for any such composite solution, we need to trust certain entities in the system such as the compiler, the BIOS, the (Java) runtime system, the hardware, digital certificates, and so on -- essentially the "chain of trust" problem. That this is a tricky problem has been shown in an interesting way by Ken Thompson [53]; we will discuss it below. Hence, we need a "small" trusted computing base (TCB): all protection mechanisms within a system (hardware, software, firmware) for enforcing security policies.
In the past (early 1960s), operating systems were small and compilers larger in comparison. The TCB could justifably be the operating system, even if uncomfortably larger than one wished. In today's context, the compilers need not be as large as current operating systems (for example, Linux kernel or Windows is many millions of lines of code), and a TCB could profitably be the compiler. Hence, a compiler analysis of security is meaningful nowadays and likely to be the only way large systems (often a distributed system) can be crafted in the future. Using a top-level security policy, it may be possible to automatically partition the program so that the resulting distributed system is secure by design [60].
To illustrate the effectiveness of static security analysis, we first discuss a case where static analysis fails completely (Ken Thomson's Trojan horse). We then outline some results on the problem of detecting viruses and then discuss a case study in which static analysis can in principle be very hard (equivalent to cryptanalysis in general) but is actually much simpler because of a critical implementation error. We will also briefly touch upon obfuscation that exploits difficulty of analysis.
We then discuss static analysis of buffer overflows, loading of mobile code, and access control and information flow, illustrating the latter using Jif [35] language on a realistic problem. We conclude with likely future directions in this area of research.
2.1.1 A Dramatic Failure of Static Analysis: Ken Thompson's Trojan Horse
Some techniques to defeat static analysis can be deeply effective; we summarize Ken Thompson's ingenious Trojan horse trick [53] in a compiler that uses self-reproduction, self-learning, and self-application. We follow his exposition closely.
First, self-reproduction is possible; for example, one can construct a self-reproducing program such as ((lambda x. (list x x)) (lambda x. (list x x))). Second, it is possible to teach a compiler (written in its own language) to compile new features (the art of bootstrapping a compiler): this makes self-learning possible. We again give Ken Thompson's example to illustrate this. Let us say that a lexer knows about '\n' (newline) but not '\v' (vertical tab). How does one teach it to compile '\v' also? Let the initial source be:

Adding to the compiler source

and using previous compiler binary does not work, as that binary does not know about '\v'. However, the following works:

Now a new binary (from the new source using the old compiler binary) knows about '\v' in a portable way. Now we can use it to compile the previously uncompilable statement:

The compiler has "learned." Now, we can introduce a Trojan horse into the login program that has a backdoor to allow a special access to log in as any user:

However, this is easily detectable (by examining the source). To make this not possible, we can add a second Trojan horse aimed at the compiler:

Now we can code a self-reproducing program that reintroduces both Trojan horses into the compiler with a learning phase where the buggy compiler binary with two Trojan horses now reinserts it into any new compiler binary compiled from a clean source! The detailed scheme is as follows: first a clean compiler binary (A) is built from a clean compiler source (S). Next, as part of the learning phase, a modified compiler source () can be built that incorporates the bugs. The logic in S' looks at the source code of any program submitted for compilation and, say by pattern matching, decides whether a program submitted is a login or a compiler program. If it decides that it is one of these special programs, it reproduces4 one or more Trojan horses (as necessary) when presented with a clean source. Let the program be compiled with A. We have a new binary A' that reinserts the two Trojans on any clean source!
It is easiest to do so in the binary being produced as the compiled output.
The virus exists in the binary but not in the source. This is not possible to discern unless the history of the system (the sequence of compilations and alterations) is kept in mind. Static analysis fails spectacularly!
2.1.2 Detecting Viruses
As discussed earlier, the virus detection problem is undecidable. A successful virus encapsulates itself so that it cannot be detected -- the opposite of "self-identifying data." For example, a very clever virus would put logic in I/O routines so that any read of suspected portions of a disk returns the original "correct" information! A polymorphic virus inserts "random" data to vary the signature. More effectively, it can create a random encryption key to encrypt the rest of the virus and store the key with the virus.
Cohen's ResultsCohen's impossibility result states that it is impossible for a program to perfectly demarcate a line, enclosing all and only those programs that are infected with some virus: no algorithm can properly detect all possible viruses [16]: does not detect Virus. For any candidate computer virus detection algorithm , there is a program p(pgm): if A(pgm) then exit; else spread. Here, spread means behave like a virus. We can diagonalize this by setting pgm=p and a contradiction follows immediately as p spreads iff not A(p).
Similarly, Chess and White [11] show there exists a virus that no algorithm perfectly detects, i.e., one with no false positives: . does not detect Virus. Also, there exists a virus that no algorithm loosely detects, i.e., claims to find the virus but is infected with some other virus: . does not loosely-detect Virus. In other words, there exist viruses for which, even with the virus analyzed completely, no program detects only that virus with no false positives. Further, another Chess and White's impossibility result states that there is no program to classify programs (only those) with a virus V and not include any program without any virus.
Furthermore, there are interesting results concerning polymorphic viruses: these viruses generate a set of other viruses that are not identical to themselves but are related in some way (for example, are able to reproduce the next one in sequence). If the size of this set is greater than 1, call the set of viruses generated the viral set S.
An algorithm detects a set of viruses iff for every program , terminates and returns TRUE iff is infected with some virus in . If is a polyvirus, for any candidate -detection algorithm , there is a program that is an instance of :

This can be diagonalized by , resulting in a contradiction: if C(s) true exit; other-wise polyvirus.
Hence, it is clear that static analysis has serious limits.
2.1.3 A Case Study for Static Analysis: GSM Security Hole
We will now attempt to situate static analysis with other analyses, using the partitioning attack [50] on GSM hashing on a particular implementation as an example. GSM uses the COMP128 algorithm for encryption. A 16B (128b) key of subscriber (available with the base station along with a 16B challenge from the base station is used to construct a 12B (96b) hash. The first 32b is sent as a response to the challenge, and the remaining 64b is used as the session key. The critical issue is that there should be no leakage of the key in any of the outputs this includes any electromagnetic (EM) leakages during the computation of the hash. The formula for computation of the hash it has a butterfly structure) is as follows:

If we expand y in the expression for X[m], we have
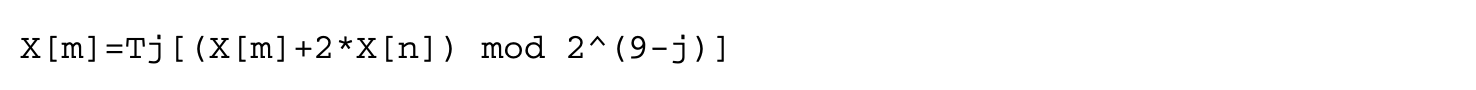
A simple-minded flow analysis will show that there is direct dependence of the EM leakage on the key; hence, this is not information flow secure. However, cryptographers, using the right "confusion" and "diffusion" operators such as the above code, have shown that the inverse can be very difficult to compute. Hence, even if very simple static analysis clearly points out the flow dependence of the EM leakage on the key, it is not good enough to crack the key. However, even if the mapping is cryptanalytically strong, "implementation" bugs can often give away the key. An attack is possible if one does not adhere to the following principle [50] of statistical independence (or more accurately noninterference, which will be discussed later): relevant bits of all intermediate cycles and their values should be statistically independent of the inputs, outputs, and sensitive information.
Normally, those bits that emit high EM are good candidates for analysis. One set of candidates are the array and index values, as they need to be amplified electrically for addressing memory. They are therefore EM sensitive, whereas other internal values may not be so.
Because of the violation of this principle, a cryptographically strong algorithm may have an implementation that leaks secrets. For example, many implementations use 8b microprocessors, as COMP128 is optimized for them, so the actual implementation for T0 is two tables, T00 and T01 (each 256 entries):

If the number of intermediate lookups from tables T00 or T01 have statistical significance, then because of the linearity of the index y with respect to R for the first round, some information can be gleaned about the key. The technique of differential cryptanalysis is based on such observations. In addition, if it is possible to know when access changes from one table (say, T00) to another (T01) by changing R, then the R value where it changes is given by K + 2*R=256, from which X, the first byte of the GSM key, can be determined.
In general, we basically have a set of constraints, such as

where and are two close values that map the index into different arrays (T0 or T1).5
In general, , with being an affine function for tractability.
If there is a solution to these Diophantine equations, then we have an attack. Otherwise, no. Since the cryptographic confusion and diffusion operations determine the difficulty (especially with devices such as S-boxes in DES), in general the problem is equivalent to the cryptanalysis problem. However, if we assume that the confusion and diffusion operations are linear in subkey and other parameters (as in COMP128), we just need to solve a set of linear Diophantine equations [39].
What we can learn from the above is the following: we need to identify EM-sensitive variables. Other values can be "dclassified"; even if we do not take any precautions, we can assume they cannot be observed from an EM perspective. We need to check the flow dependence of the EM-sensitive variables (i.e., externally visible) on secrets that need to be safeguarded.
Recently, work has been done that implies that success or failure of branch prediction presents observable events that can be used to crack encryption keys.
The above suggests the following problems for study:
- Automatic downgrading of "insensitive" variables
- Determination of the minimal declassification to achieve desired flow properties
2.1.4 Obfuscation
Given that static analyses are often hard, some applications use them to good effect. An example is the new area of "obfuscation" of code so that it cannot be reverse-engineered easily. Obfuscation is the attempt to make code "unreadable" or "unintelligible" in the hope that it cannot be used by competitors. This is effected by performing semantic-preserving transformations so that automatic static analysis can reveal nothing useful. In one instance, control flow is intentionally altered so that it is difficult to understand or use it by making sure that any analysis that can help in unravelling code is computationally intractable (for example, PSPACE-hard or NP-hard). Another example is intentionally introducing aliases, as certain alias analysis problems are known to be hard (if not undecidable), especially in the interprocedural context. Since it has been shown that obfuscation is, in general, impossible [4], static analysis in principle could be adopted to undo obfuscation unless it is computationally hard.
2.2 Static Analysis of Buffer Overflows
Since the advent of the Morris worm in 1988, buffer overflow techniques to compromise systems have been widely used. Most recently, the SQL slammer worm in 2003, using a small UDP packet (376B), compromised 90% of all target machines worldwide in less than 10 minutes.
Since buffer overflow on a stack can be avoided, for example, by preventing the return address from being overwritten by the "malicious" input string, array bounds checking the input parameters by the callee is one technique. Because of the cost of this check, it is useful to explore compile time approaches that eliminate the check through program analysis. Wagner et al. [56] use static analysis (integer range analysis), but it has false positives due to imprecision in pointer analysis, interprocedural analysis, and so on and a lack of information on dynamically allocated sizes.
CCured [46] uses static analysis to insert runtime checks to create a type-safe version of C program. CCured classifies C pointers into SAFE, SEQ, or WILD pointers. SAFE pointers require only a null check. SEQ pointers require a bounds check, as these are involved in pointer arithmetic, but the pointed object is known statically, while WILD ones require a bounds check as well as a runtime check, as it is not known what type of objects they point to at runtime. For such dynamically typed pointers, we cannot rely on the static type; instead, we need, for example, runtime tags to differentiate pointers from nonpointers.
Ganapathy et al. [23] solve linear programming problems arising out of modeling C string programs as linear programs to identify buffer overruns. Constraints result from buffer declarations, assignments, and function call/returns. C source is first analyzed by a tool that builds a program-dependence graph for each procedure, an interprocedural CFG, ASTs for expressions, along with points-to and side-effect information. A constraint generator then generates four constraints for each pointer to a buffer (between max/min buffer allocation and max/min buffer index used), four constraints on each index assignment (between previous and new values as well as for the highest and lowest values), two for each buffer declaration, and so on. A taint analysis next attempts to identify and remove any uninitialized constraint variables to make it easy for the constraint solvers.
Using LP solvers, the best possible estimate of the number of bytes used and allocated for each buffer in any execution is computed. Based on these values, buffer overruns are inferred. Some false positives are possible because of the flow-insensitive approach followed; these have to be manually resolved. Since infeasible linear programs are possible, they use an algorithm to identify irreducibly inconsistent sets. After such sets of constraints are removed, further processing is done before solvers are employed. This approach also employs techniques to make program analysis context sensitive.
Engler et al. [19] use a "metacompilation" (MC) approach to catch potential security holes. For example, any use of "untrusted input"6 could be a potential security hole. Since a compiler potentially has information about such input variables, a compiler can statically infer some of the problematic uses and flag them. To avoid hardwiring some of these inferences, the MC approach allows implementers to add rules to the compiler in the form of high-level system-specific checkers. Jaeger et al. [31] use a similar approach to make SELinux aware of two trust levels to make information flow analysis possible; as of now, it is not possible. We will discuss this further in Section 2.4.3.
Examples in the Linux kernel code are system call parameters, routines that copy data from user space, and network data.
2.3 Static Analysis of Safety of Mobile Code
The importance of safe executable code embedded in web pages (such as Javascript), applications (as macros in spreadsheets), OS kernel (such as drivers, packet filters [44], and profilers such as DTrace [51]), cell phones, and smartcards is increasing every day. With unsafe code (especially one that is a Trojan), it is possible to get elevated privileges that can ultimately compromise the system. Recently, Google Desktop search [47] could be used to compromise a machine (to make all of its local files available outside, for example) in the presence of a malicious Java applet, as Java allows an applet to connect to its originating host.
The most simple model is the "naive" sandbox model where there are restrictions such as limited access to the local file system for the code, but this is often too restrictive. A better sandbox model is that of executing the code in a virtual machine implemented either as an OS abstraction or as a software isolation layer and using emulation. In the latter solution, the safety property of the programming language and the access checks in the software isolation layer are used to guarantee security.
Since object-oriented (OO) languages such as Java and C# have been designed for making possible "secure" applets, we will consider OO languages here. Checking whether a method has access permissions may not be local. Once we use a programming language with function calls, the call stack has information on the current calling sequence. Depending on this path, a method may or may not have the permissions. Stack inspection can be carried out to protect the callee from the caller by ensuring that the untrusted caller has the right credentials to call a higher-privileged or trusted callee. However, it does not protect the caller from the callee in the case of callback or event-based systems. We need to compute the intersection of permissions of all methods invoked per thread and base access based on this intersection. This protects in both directions.
Static analysis can be carried out to check security loopholes introduced by extensibility in OO languages. Such holes can be introduced through subclassing that overrides methods that check for corner cases important for security. We can detect potential security holes by using a combination of model checking and abstract interpretation: First, compute all the possible execution histories; pushdown systems can be used for representation. Next, use temporal logic to express properties of interest (for example, a method from an applet cannot call a method from another applet). If necessary, use abstract interpretation and model checking to check properties of interest.
Another approach is that of the proof-carrying code (PCC). Here, mobile code is accompanied by a proof that the code follows the security policy. As a detailed description of the above approaches for the safety of mobile code is given in the first edition of this book [36], we will not discuss it here further.
2.4 Static Analysis of Access Control Policies
Lampson [38] introduced access control as a mapping from {entity, resource, op} to {permit, deny} (as commonly used in operating systems). Later models have introduced structure for entities such as roles ("role-based access control") and introduced a noop to handle the ability to model access control modularly by allowing multiple rules to fire: {role, resource, op} to {permit, deny, noop}. Another significant advance is access control with anonymous entities: the subject of trust management, which we discuss in Section 2.4.4.
Starting from the early simple notion, theoretical analysis in the HRU system [29] of access control has the following primitives:
- Create subject : creates a new row, column in the access control matrix (ACM)
- Create object : creates a new column in the ACM
- Destroy subject : deletes a row, column from the ACM
- Destroy object : deletes a column from the ACM
- Enter into
A[s,o]: adds rights for subject over object - Delete from
A[s, o]: removes rights from subject over object Adding a generic right where there was not one is "leaking." If a system S, beginning in initial state , cannot leak right , it is safe with respect to the right . With the above primitives, there is no algorithm for determining whether a protection system S with initial state is safe with respect to a generic right . A Turing machine can be simulated by the access control system by the use of the infinite two-dimensional access control matrix to simulate the infinite Turing tape, using the conditions to check the presence of a right to simulate whether a symbol on the Turing tape exists, adding certain rights to keep track of where the end of the corresponding tape is, and so on.
Take grant models [7], in contradistinction to HRU models, are decidable in linear time [7]. Instead of generic analysis, specific graph models of granting and deleting privileges and so on are used. Koch et al. [37] have proposed an approach in which safety is decidable in their graphical model if each graph rule either deletes or adds graph structure but not both. However, the configuration graph is fixed.
Recently, work has been done on understanding and comparing the complexity of discretionary access control (DAC) (Graham-Denning) and HRU models in terms of state transition systems [42]. HRU systems have been shown to be not as expressive as DAC. In the Graham-Denning model, if a subject is deleted, the objects owned are atomically transferred to its parent. In a highly available access control system, however, there is usually more than one parent (a DAG structure rather than a tree), and we need to decide how the "orphaned" objects are to be shared. We need to specify further models (for example, dynamic separation of duty). If a subject is the active entity or leader, further modeling is necessary. The simplest model usually assumes a fixed static alternate leader, but this is inappropriate in many critical designs. The difficulty in handling a more general model is that leader election also requires resources that are subject to access control, but for any access control reconfiguration to take place, authentications and authorizations have to be frozen for a short duration until the reconfiguration is complete. Since leader election itself requires access control decisions, as it requires network, storage, and other resources, we need a special mechanism to keep these outside the purview of the freeze of the access control system. The modeling thus becomes extremely complex. This is an area for investigation.
2.4.1 Case Studies
2.4.1.1 Firewalls
Firewalls are one widely known access control mechanism. A firewall examines each packet that passes through the entry point of a network and decides whether to accept the packet and allow it to proceed or to discard the packet. A firewall is usually designed as a sequence of rules; each rule is of the form preddecision, where pred is a boolean expression over the different fields of a packet, and the decision is either accept or discard. Designing the sequence of rules for a firewall is not an easy task, as it needs to be consistent, complete, and compact. Consistency means the rules are ordered correctly, completeness means every packet satisfies at least one rule in the firewall, and compactness means the firewall has no redundant rules. Gouda and Liu [25] have examined the use of "firewall decision diagrams" for automated analysis and present polynomial algorithms for achieving the above desirable goals.
2.4.1.2 Setuid Analysis
The access control mechanism in Unix-based systems is based critically on the setuid mechanism. This is known to be a source of many privilege escalation attacks if this feature is not used correctly. Since there are many variations of setuid in different Unix versions, the correctness of a particular application using this mechanism is difficult to establish across multiple Unix versions. Static analysis of an application along with the model of the setuid mechanism is one attempt at checking the correctness of an application.
Chen et al. [10] developed a formal model of transitions of the user IDs involved in the setuid mechanism as a finite-state automaton (FSA) and developed techniques for automatic construction of such models. The resulting FSAs are used to uncover problematic uses of the Unix API for uid-setting system calls, to identify differences in the semantics of these calls among various Unix systems, to detect inconsistency in the handling of user IDs within an OS kernel, and to check the proper usage of these calls in programsautomatically. As a Unix-based system maintains per-process state (e.g., the real, effective, and saved uids) to track privilege levels, a suitably abstracted FSA (by mapping all user IDs into a single "nonroot" composite ID) can be devised to maintain all such relevant information per state. Each uid-setting system call then leads to a number of possible transitions; FSA transitions are labeled with system calls. Let this FSA be called the setiud-FSA. The application program can also be suitably abstracted and modeled as an FSA (the program FSA) that represents each program point as a state and each statement as a transition. By composing the program FSA with the setiud-FSA, we get a composite FSA. Each state in the composite FSA is a pair of one state from the setiud-FSA (representing a unique combination of the values in the real uid, effective uid, and saved uid) and one state from the program FSA (representing a program point). Using this composite FSA, questions such as the following can be answered:
- Can the setiud system call fail? This is possible if an error state in the setiud-FSA part in a composite state can be reached.
- Can the program fail to drop the privilege? This is possible if a composite state can be reached that has a privileged setiud-FSA state, but the program state should be unprivileged at that program point.
- Which parts of an application run at elevated privileges? By examining all the reachable composite states, this question can be answered easily.
2.4.2 Dynamic Access Control
Recent models of access control are declarative, using rules that encode the traditional matrix model. An access request is evaluated using the rules to decide whether access is to be provided or not. It also helps to separate access control policies from business logic.
Dougherty et al. [18] use Datalog to specify access control policies. At any point in the evolution of the system, facts ("ground terms") interact with the policies ("datalog rules"); the resulting set of deductions is a fixpoint that can be used to answer queries whether an access is to be allowed or not. In many systems, there is also a temporal component to access control decisions. Once an event happens (e.g., a paper is assigned to reviewer), certain accesses get revoked (e.g., the reviewer cannot see the reviews of other reviewers of the same paper until he has submitted his own) or allowed. We can therefore construct a transition system with edges being events that have a bearing on the access control decisions. The goal of analysis is now either safety or availability (a form of liveness): namely, is there some accessible state in the dynamic access model that satisfies some boolean expression over policy facts? These questions can be answered efficiently, as any fixed Datalog query can be computed in polynomial time in the size of the database, and the result of any fixed conjunctive query over a database can be computed in space O(logl ) [18, 54].
Analysis of access control by abstract interpretation is another approach. Given a language for access control, we can model leakage of a right as an abstract interpretation problem. Consider a simple language with assignments, conditionals, and sequence (","). If is a user, let represent whether can execute in state . Let mean that can read in state and means can write in state . Then we have the following interpretation:
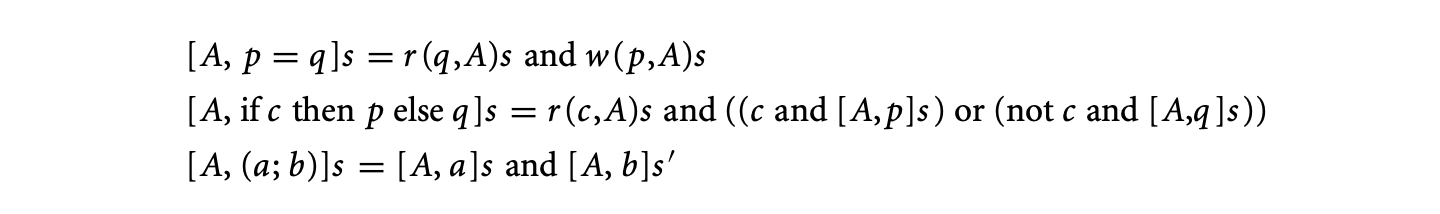 where is the new state after executing .
where is the new state after executing .
Here, can be a set of users also. Next, if , then can execute prog. The access control problem now becomes: Is there a program that can execute and that computes the value of some, forbidden, value and writes it to a location that can access? With HRU-type models, the set of programs to be examined is essentially unbounded, and we have undecidability. However, if we restrict the programs to be finite, decidability is possible.
It is also possible to model dynamic access control by other methods such as using pushdown systems [34], graph grammars [5], but we will only discuss the access control problem on the Internet that can be modeled using pushdown systems.
2.4.3 Retrofitting Simple MAC Models for SELinux
Since SELinux is easily available, we will use it as an example for discussing access control. In the past, the lack of such operating systems made research difficult; they were either classified or very expensive.
Any machine hosting some services on the net should not get totally compromised if there is a break-in. Can we isolate the breach to those services and not let it affect the rest of the system? It is possible to do so if we can use mandatory access policies (MACs) rather than the standard DACs. In a MAC the system decides how you share your objects, whereas in a DAC you can decide how you share your objects. A break-in into a DAC system has the potential to usurp the entire machine, whereas in a MAC system the kernel or the system still validates each access according to a policy loaded beforehand.
For example, in some recent Linux systems (e.g., Fedora Core 5/6, which is based on SELinux) that employ MAC, there is a "targeted" policy where every access to a resource is allowed implicitly, but deny rules can be used to prevent accesses. By default, most processes run in an "unconfined" domain, but certain daemons or processes7 (targeted ones) run in "locked-down" domains after starting out as unconfined. If cracker breaks into apache and gets a shell account, it can run only with the privileges of the locked-down daemon, and the rest of the system is usually safe. The rest of the system is not safe only if there is a way to effect a transition into the unconfined domain. With the more stringent "strict policy," also available in Fedora Core 5/6, that implicitly denies everything and "allow" rules are used to enable accesses, it is even more difficult.
httpd, dhcpd, mailman, mysqld, named, nscd, ntpd, portmap, postgresql, squid, syslogd, winbind, and snmpd.
Every subject (process) and object (e.g., file, socket, IPC object, etc.) has a security context that is interpreted only by a security server. Policy enforcement code typically handles security identifiers (SIDs); SIDs are nonpersistent and local identifiers. SELinux implements a combination of:
- Type enforcement and (optional) multilevel security: Typed models have been shown to be more tractable for analysis. Type enforcement requires that the type of domains and objects be respected when making transitions to other domains or when acting on objects of a certain type. It also offers some preliminary support for models that have information at different levels of security. The bulk of the rules in most policies in SELinux are for type enforcement.
- Role-based access control (RBAC): Roles for processes. Specifies domains that can be entered by each role and specifies roles that are authorized for each user with an initial domain associated with each user role. It has the ease of management of RBAC with fine granularity of type enforcement.
The security policy is specified through a set of configuration files.
However, one downside is that very fine level control is needed. Every major component such as NFS or X needs extensive work on what permissions need to be given before it can do its job. As the default assumption is "deny," there could be as many as 30,000 allow rules. There is a critical need for automated analysis. If the rules are too lax, we can have a security problem. If we have too few rules (too strict), a program can fail at runtime, as it does not have enough permissions to carry out its job. Just as in software testing, we need to do code coverage analysis. In the simplest case, without alias analysis or interprocedural analysis, it is possible to look at the static code and decide what objects are needed to be accessed. Assuming that all the paths are possible, one can use abstract interpretation or program slicing to determine the needed rules. However, these rules will necessarily be conservative. Without proper alias analysis in the presence of aliasing, we will have to be even more imprecise; similar is the case in the context of interprocedural analysis.
Ganapathy et al. [22] discuss automated authorization policy enforcement for user-space servers and the Linux kernel. Here, legacy code is retrofitted with calls to a reference monitor that checks permissions before granting access (MAC). For example, information "cut" from a sensitive window in an X server should not be allowed to be "pasted" into an ordinary one. Since manual placing of these calls is error prone, an automated analysis based on program analysis is useful. First, security-sensitive operations to be checked ("MACed") are identified. Next, for each such operation, the code-level constructs that must be executed are identified by a static analysis as a conjunction of several code-level patterns in terms of their ASTs. Next, locations where these constructs are potentially performed have to be located and, where possible, the "subject" and "object" identified. Next the server or kernel is instrumented with calls to a reference monitor with subject, object, and op triple as the argument, with a jump to the normal code on success or with call to a code that handles the failure case.
We now discuss the static analysis for automatic placement of authorization hooks, given, for example, the kernel code and the reference monitor code [21]. Assuming no recursion, the call graph of the reference monitor code is constructed. For each node in the call graph, a summary is produced. A summary of a function is the set of pairs that denotes the condition under which can be authorized by the function. For computing the summary, a flow and context-sensitive analysis is used that propagates a predicate through the statements of the function. For example, at a conditional statement with as the condition, the "if" part is analyzed with , and the "then" part by . At a call site, each pair in the summary of the function is substituted with the actuals of the call, and the propagation of the predicate continues. When it terminates, we have a set of pairs as summary. Another static analysis on the kernel source recovers the set of conceptual operations that may be performed by each kernel function. This is done by searching for combinations of code patterns in each kernel function. For each kernel function, it then searches through a set of idioms for these code patterns to determine if the function performs a conceptual operation; an idiom is a rule that relates a combination of code patterns to conceptual operations.
Once the summary of each function in the reference monitor code and the set of conceptual operations () for each kernel function is available, finding the set of functions in the monitor code that guards reduces to finding a cover for the set using the summary of functions .
Another tractable approach is for a less granular model but finer than non-MAC systems. For example, it is typically the case in a large system that there are definitely forbidden accesses and allowable accesses but also many "gray" areas. "Conflicting access control subspaces" [32] result if assignments of permissions and constraints that prohibit access to a subject or a role conflict. Analyzing these conflicts and resolving them, an iterative procedure, will result in a workable model.
2.4.4 Model Checking Access Control on the Internet: Trust Management
Access control is based on identity. However, on the Internet, there is usually no relationship between requestor and provider prior to request (though cookies are one mechanism used). When users are unknown, we need third-party input so that trust, delegation, and public keys can be negotiated. Withpublic key cryptography, it becomes possible to deal with anonymous users as long as they have a public key: authentication/authorization is now possible with models such as SPKI/SDSI (simple public key infrastructure/simple distributed security infrastructure) [15] or trust management. An issuer authorizes specific permissions to specific principals; these credentials can be signed by the issuer to avoid tampering. We can now have credentials (optionally with delegation) with the assumption that locally generated public keys do not collide with other locally generated public keys elsewhere. This allows us to exploit local namespaces: any local resource controlled by a principal can be given access permissions to others by signing this grant of permission using the public key.
We can now combine access control and cryptography into a larger framework with logics for authentication/authorization and access control. For example, an authorization certificate (K, S, D, T, V) in SPKI/SDSI can be viewed as an ACL entry, where keys or principals represented by the subject S are given permission, by a principal with public key K, to access a "local" resource T in the domain of the principal with public key K. Here, T is the set of authorizations (operations permitted on T), D is the delegation control (whether S can in turn give permissions to others), and V is the duration during which the certificate is valid.
Name certificates define the names available in an issuer's local namespace, whereas authorization certificates grant authorizations or delegate the ability to grant authorizations. A certificate chain provides proof that a client's public key is one of the keys that has been authorized to access a given resource either directly or transitively, via one or more name definition or authorization delegation steps. A set of SPKI/SDSI name and authorization certificates defines a pushdown system [34], and one can "model check" many of the properties in polynomial time. Queries in SPKI/SDSI [15] can be as follows:
- Authorized access: Given resource R and principal K, is K authorized to access R? Given resource R and name N (not necessarily a principal), is N authorized to access R? Given resource R, what names (not necessarily principals) are authorized to access R?
- Shared access: For two given resources R1 and R2, what principals can access both R1 and R2? For two given principals K1 and K2, what resources can be accessed by both K1 and K2?
- Compromisation assessment: Due (solely) to the presence of maliciously or accidentally issued certificate set C0 C, what resources could principal K have gained access to? What principals could have gained access to resource R?
- Expiration vulnerability: If certificate set C0 C expires, what resources will principal K be prevented from accessing? What principals will be excluded from accessing resource R?
- Universally guarded access: Is it the case that all authorizations that can be issued for a given resource R must involve a cert signed by principal K? Is it the case that all authorizations that grant a given principal K0 access to some resource must involve a cert signed by K?
Other models of trust management such as RBAC-based trust management (RT) [41] are also possible. The following rules are available in the base model RT[]:
- Simple member: . A asserts that D is a member of A's role.
- Simple inclusion: . This is delegation from A to B.
The model RT[] adds to RT[] the following intersection inclusion rule: and . This adds partial delegations from A to B1 and to B2. The model RT[] adds to RT[] the following linking inclusion rule: . This adds delegation from A to all the members of the role RT[] is all of the above four rules. The kinds of questions we would like to ask are:
- Simple safety (existential): Does a principal have access to some resource in some reachable state?
- Simple availability: In every state, does some principal have access to some resource?
- Bounded safety: In every state, is the number of principals that have access to some resource bounded?
- Liveness (existential): Is there a reachable state in which no principal has access to a given resource? Mutual exclusion: In every reachable state, are two given properties (or two given resources) mutually exclusive (i.e., no principal has both properties [or access to both resources] at the same time)?
- Containment: In every reachable state, does every principal that has one property (e.g., has access to a resource) also have another property (e.g., is an employee)? Containment can express safety or availability (e.g., by interchanging the two example properties in the previous sentence).
The complexity of queries such as simple safety, simple availability, bounded safety, liveness, and mutual exclusion analysis for is decidable in poly time in size of state. For containment analysis [41], it is P for , coNP-complete for , PSPACE-complete for , and decidable in coNEXP for .
However, permission-based trust management cannot easily authorize principals with a certain property. For example [41], to give a 20% discount to students of a particular institute, the bookstore can delegate discount permission to the institute key. The institute has to delegate its key to each student with respect to "bookstore" context; this can be too much burden on the institute. Alternatively, the institute can create a new group key for students and delegate it to each student key, but this requires that the institute create a key for each meaningful group; this is also too much burden. One answer to this problem is an attribute-based approach, which combines RBAC and trust management.
The requirements in an attribute-based system [40] are decentralization, provision of delegation of attribute authority, inference, attribute-based delegation of attribute authority, conjunction of attributes, attributes with fields (expiry, age, etc.) with the desirable features of expressive power, declarative semantics, and tractable compliance checking. Logic programming languages such as Prolog or, better, Datalog can be used for a delegation logic for ABAC: this combines logic programming with delegation and possibly with monotonic or nonmonotonic reasoning. With delegation depth and complex principals such as out of (static/dynamic) thresholds, many more realistic situations can be addressed.
Related to the idea of attribute-based access control and to allow for better interoperability across administrative boundaries of large systems, an interesting approach is the use of proof-carrying authentication [2]. An access is allowed if a proof can be constructed for an arbitrary access predicate by locating and using pieces of the security policy that have been distributed across arbitrary hosts. It has been implemented as modules that extend a standard web server and web browser to use proof-carrying authorization to control access to web pages. The web browser generates proofs mechanically by iteratively fetching proof components until a proof can be constructed. They provide for iterative authorization, by which a server can require a browser to prove a series of challenges.
2.5 Language-Based Security
As discussed earlier, current operating systems are much bigger than current compilers, so it is worthwhile to make the compiler part of the TCB rather than an OS. If it is possible to express security policies using a programming language that can be statically analyzed, a compiler as part of a TCB makes eminent sense.
The main goal of language-based security is to check the noninterference property, that is, to detect all possible leakages of some sensitive information through computation, timing channels, termination channels, I/O channels, and so on. However, the noninterference property is too restrictive to express security policies, since many programs do leak some information. For example, sensitive data after encryption can be leaked to the outside world, which is agreeable with respect to security as long as the encryption is effective. Hence, the noninterference property has to be relaxed by some mechanisms like declassification.
Note that static approaches cannot quantify the leakage of information, as the focus is on whether a program violated some desired property with respect to information flow. It is possible to use a dynamic approach that quantifies the amount of information leaked by a program as the entropy of the program's outputs as a distribution over the possible values of the secret inputs, with the public inputs held constant [43]. Noninterference has an entropy of 0. Such a quantitative approach will often be more useful and flexible than a strict static analysis approach, except that analysis has to be repeated multiple times for coverage.
One approach to static analysis for language-based security has been to use type inference techniques, which we discuss next.
2.5.1 The Type-Based Approach
Type systems establish safety properties (invariants) that hold throughout the program, whereas noninterference requires that two programs give the same output in spite of different input values for their "low" values. Hence, a noninterference proof can be viewed as a bisimulation. For simpler languages (discussed below), a direct proof is possible, but for languages with advanced features such as concurrency and dynamic memory allocation, noninterference proofs are more complex. Before we proceed to discuss the type-based approach, we will briefly describe the lattice model of information flow.
The lattice model of information flow started with the work of Bell and LaPadula [6] and Denning and Denning [17]. Every program variable has a static security class (or label); the security label of each variable can be global (as in early work) or local for each owner, as in the decentralized label model (DLM) developed for Java in Jif [45].
If and are variables, and there is (direct) information flow from to , it is permissible iff the label of is less than that of . Indirect flows arise from control flow such as if (y=1) then x=1 else x=2. If the label of the label of , some information of flows into (based on whether is 1 or 2) and should be disallowed. Similarly, if (y=z) then x=1 else w=2, the of the levels of and should be of the levels of and . To handle this situation, we can assign a label to the program counter (). In the above example, we can assign the label of the to just after evaluating the condition; the condition now that needs to be satisfied is that both the arms of the if should have at least the same level as the .
Dynamic labels are also possible. A method may take parameters, and the label of the parameter itself could be an another formal. In addition, array elements could have different labels based on index, and hence an expression could have a dynamic label based on the runtime value of its index.
Checking that the static label of an expression is at least as restrictive as the dynamic label of any value it might produce is now one goal of analysis (preferably static). Similarly, in the absence of declassification, we need to check that the static label of a value is at least as restrictive as the dynamic label of any value that might affect it. Because of the limitations of analysis, static checking may need to use conservative approximations for tractability.
Denning and Denning proposed program certification as a lattice-based static analysis method [17] to verify secure information flow. However, soundness of the analysis was not addressed. Later work such as that of Volpano and colleagues [55] showed that a program is secure if it is "typable," with the "types" being labels from a security lattice. Upward flows are handled through subtyping. In addition to checking correctness of flows, it is possible to use type inference to reduce the need to annotate the security levels by the programmer. Type inference computes the type of any expression or program. By introducing type variables, a program can be checked if it can be typed by solving the constraint equations (inequalities) induced by the program. In general, simple type inference is equivalent to first-order unification, whereas in the context of dependent types it is equivalent to higher-order unification.
For example, consider a simple imperative language with the following syntax [55]:

Here, l denotes locations (i.e., program counter values), n integers, x variables, and c constants. The types in this system are types of variables, locations, expressions, and commands; these are given by one of the partially ordered security labels of the security system. A cmd has a type only if it is guaranteedthat every assignment in cmd is made to a variable whose security class is t or higher. The type system for security analysis is as follows ( and are location and type environments, respectively):

Consider the rules for assignment above. In order for information to flow from to , both have to be at the same security level. However, upward flow is allowed, for secrecy, for example, if is at a higher level and is at a lower level. This is handled by extending the partial order by subtyping and coercion: the low level (derived type) is smaller (for secrecy) in this extended order than the high level (base type). Note that the extended relation has to be contravariant in the types of commands .
It can be proved [55] that if an expression can be given a type in the above type system, then, for secrecy, only variables at level or lower in will have their contents read when is evaluated (no read up). For integrity, every variable in stores information at integrity level . If a command has the property that every assignment within is made to a variable whose security class is at least , then the confinement property for secrecy says that no variable below level is updated in (no write down). For integrity, every variable assigned in can be updated by a type variable.
Soundness of the type system induces the noninterference property, that is, a high value cannot influence any lower value (or information does not leak from high values to low values).
Smith and Volpano [53] have studied information flow in multithreaded programs. The above type system does not guarantee noninterference; however, by restricting the label of all the while-loops and its guards to low, the property is restored. Abadi has modeled encryption as declassification [1] and presented the resulting type system.
Myers and colleagues have developed static checking for DLM-based Jif language [12, 16], while Pottier and colleagues [49] have developed OCaml-based FlowCAML. We discuss the Jif approach in some detail.
2.5.2 Java Information Flow (Jif) Language
Jif is a Java-based information flow programming language that adds static analysis of information flow for improved security assurance. Jif is mainly based on static type checking. Jif also performs some runtime information flow checks.
Jif is based on decentralized labels. A label in Jif defines the security level, represented by a set of policy expressions separated by semicolons. A policy expression means the principal owner wants to allow labeled information to flow to at most the principal's reader. Unlike the MAC model, these labels contain fine-grained policies, which have an advantage of being able to represent decentralized access control. These labels are called decentralized labels because they enforce security on behalf of the owning principals, not on behalf of an implicitly centralized policy specifier. The policy specifies that both and own the information with each allowing either or , respectively. For integrity, another notation is adopted.
Information can flow from label to label only if (i.e., is less restrictive than ), where defines a preorder on labels in which the equivalence classes form a join semilattice. To label an expression (such as ), a join operator is defined as the lub of the labels of the operands, as it has to have a secrecy as strong as any of them. In the context of control flow, such as if cond then x=... else x=..., we also need the join operator. To handle implicit flows through control flow, each program visible location is given an implicit label.
A principal hierarchy allows one principal to actfor another. This helps in simplifying the policy statements in terms of representation of groups or roles. For example, suppose principal Alice actsfor Adm and principal Bob actsfor Adm; thus, in the following code whatever value Adm has is also readable by Alice and Bob.

The declassification mechanism gives the programmer an explicit escape hatch for releasing information whenever necessary. The declassification is basically carried out by relaxing the policies of some labels by principals having sufficient authority. For example,

Jif has label polymorphism. This allows the expression of code that is generic with respect to the security class of the data it manipulates. For example,

To the above function (which assures a security level up to {Alice;Bob:}) one can pass any integer variable having one of the following labels:

Jif has automatic label inference. This makes it unnecessary to write many type-annotations. For example, suppose the following function is called (which can only be called from a program point with label at most {Alice;Bob:}) from a valid program point; "a" will get a default label of {Alice;Bob:}.

Runtime label checking and first-class label values in Jif make it possible to discover and define new policies at runtime. Runtime checks are statically checked to ensure that information is not leaked by the success or failure of the runtime check itself. Jif provides a mechanism for comparing runtime labels and also a mechanism for comparing runtime principals. For example,

Note that in the above function n(...), "lbl represents an actual label held by the variable lbl, whereas just lbl inside a label represents the label of the variable lbl (i.e., {} here).
Labels and principals can be used as first-class values represented at runtime. These dynamic labels and principals can be used in the specification of other labels and used as the parameters of parameterized classes. Thus, Jif's type system has dependent types. For example,

Note that, unlike in Java, method arguments in Jif are always implicitly final. Some of the limitations of Jif are that there is no support for Java Threads, nested classes, initializer blocks, or native methods.
Interaction of Jif with existing Java classes is possible by generating Jif signatures for the interface corresponding to these Java classes.
2.5.3 A Case Study: VSR
The context of this section8 is the security of archival storage. The central objective usually is to guarantee the availability, integrity, and secrecy of a piece of data at the same time. Availability is usually achieved through redundancy, which reduces secrecy (it is sufficient for the adversary to get one copy of the secret). Although the requirements of availability and secrecy seem to be in conflict, an information-theoretic secret sharing protocol was proposed by Shamir in 1979 [51], but this algorithm does not provide data integrity. Loss of shares can be tolerated up to a threshold but not to arbitrary modifications of shares.
This is joint work with a former student, S. Roopesh.
A series of improvements have therefore been proposed over time to build secret sharing protocols resistant to many kinds of attacks. The first one takes into account the data-integrity requirement and leads to verifiable secret sharing (VSS) algorithms [20, 48]. The next step is to take into account mobile adversaries that can corrupt any number of parties given sufficient time. It is difficult to limit the number of corrupted parties on the large timescales over which archival systems are expected to operate. An adversary can corrupt a party, but redistribution can make that party whole again (in practice, this happens, for example, following a system re-installation). Mobile adversaries can be tackled by means of proactive secret sharing (PSS), wherein redistributions are performed periodically. In one approach, the secret is reconstructed and then redistributed. However, this causes extra vulnerability at the node of reconstruction. Therefore, another approach, redistribution without reconstruction, is used [33]. A combination of VSS and PSS is verifiable secret redistribution (VSR); one such protocol is proposed in [58]. In [26] we proposed an improvement of this protocol, relaxing some of the requirements.
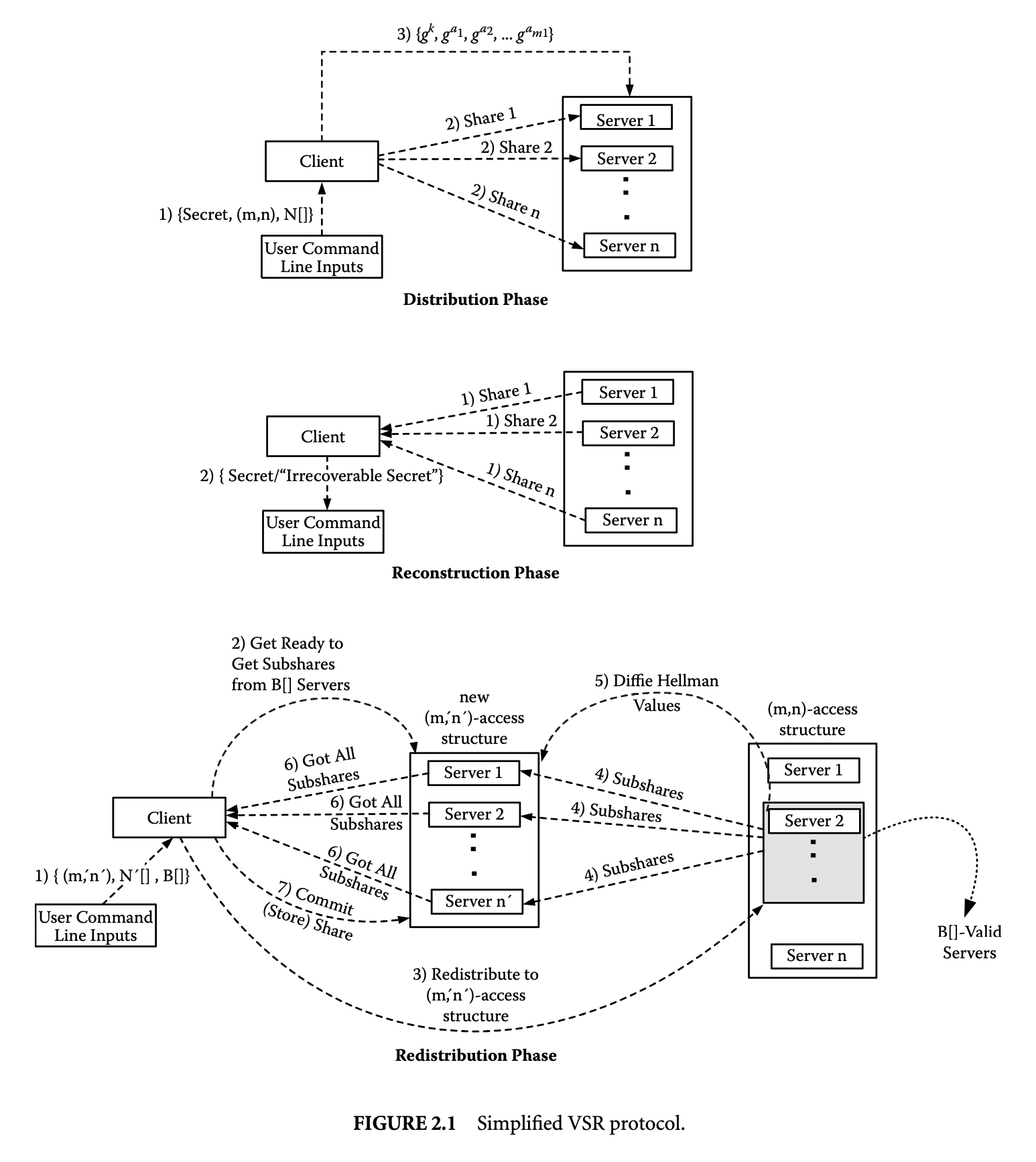
Modeling the above protocol using Jif can help us understand the potential and the difficulties of Jif static analysis. We now discuss the design of a simplified VSR [58] protocol:
-
Global values: This class contains the following variables that are used for generation and verification of shares and subshares during reconstruction and redistribution phases. (m,n): is the threshold number of servers required for reconstruction of a secret, and is the total number of servers to which shares are distributed. p: The prime used for ; is the prime used for . g: The Diffie-Hellman exponentiator. KeyID: Unique for each secret across all clients. ClientID: ID of the owner of the secret.
-
Secret: This class contains secret's value (i.e., the secret itself), the polynomial used for distribution of shares, N[] -- the array of server IDs to which the shares are distributed.
-
Points2D: This class contains two values x and f(x), where is the polynomial used for generating the shares (or subshares). It is used by Lagrangian interpolator to reconstruct the secret (or shares from subshares).
-
Share: This class contains an immutable original share value (used to check whether shares are uncorrupted or not) and a redistributing polynomial (used for redistribution of this share to a new access structure).
-
SubShare: This is the same as the Share class, except that the share value actually contains a subshare value and no redistributing polynomial.
-
SubShareBox: This class keeps track of the subshares from a set of valid servers (i.e., B[] servers) in the redistribution phase. This is maintained by all servers belonging to the new (m,n)-access structure to which new shares are redistributed.
-
Client: This class contains zero or more secrets and is responsible for initial distribution of shares and reconstruction of secrets from valid sets of servers.
-
Server: This class maintains zero or more shares from different clients and is responsible for redistribution of shares after the client (who is the owner of the secret corresponding to this share) has approved the redistribution.
-
Node: Each node contains two units, one Client and the other Server (having the same IDs as this node). On message reception from the reliable communication (group communication system [GCS]) interface GCSInterface, this node extracts the information inside the message and gives it to either the client or the server, based on the message type.
-
GCSInterface: This communication interface class is responsible for acting as an interface between underlying reliable messaging systems (e.g., the Ensemble GCS [30] system), user requests, and Client and Server.
-
UserCommand (Thread): This handles three types of commands from the user: Distribution of the user's secret to (m,n)-access structure Redistribution from (m,n)-access structure Reconstruction of secret
-
SendMessage (Thread): This class packetizes the messages (from Node) (depends on the communication interface), then either sends or multicasts these packets to the destination node(s).
-
Attacker: This class is responsible for attacking the servers, getting their shares, and corrupting all their valid shares (i.e., changing the values in the Points2D class to arbitrary values). This class also keeps all valid shares it got by attacking the servers. It also reconstructs all possible secrets from the shares collected. Without loss of generality, we assume that at most one attacker can be running in the whole system.
-
AttackerNode: This is similar to Node, but instead of Client and Server instances, it contains only one instance of the Attacker class.
-
AttackerGCSInterface: Similar to the GCSInterface class.
-
AttackerUserCommand: This handles two types of commands from the attacker: Attack server S Construct all possible secrets from collected valid shares
We do not dwell on some internal bookkeeping details during redistribution and reconstruction phases. Figure 2.1 gives the three phases of the simplified VSR protocol. The distribution and reconstruction phases almost remain the same. Only the redistribution phase is slightly modified, where the client acts as the manager of the redistribution process. The following additional assumptions are also made:
-
There are no "Abort" or "Commit" messages from servers.
-
In the redistribution phase, the client, who is the owner of the secret corresponding to this redistribution process, will send the "commit" messages instead of the redistributing servers.
-
Attacker is restricted to only attacking the servers and thereby getting all the original shares, which are held by the servers, and corrupting them.
-
There are no "reply and DoS attacks" messages.
2.5.3.1 Jif Analysis of Simplified VSR
In this section, we discuss an attempt to do a Jif analysis on a simplified VSR implementation and its difficulties. As shown in Figure 2.2, every Node (including the AttakerNode) runs with "root" authority (who is above all and can actfor all principals). Every message from and out of the network will have an empty label (as we rely on underlying Java Ensemble for cryptographically perfect end-to-end and multicast communication). The root (i.e., Node) receives the message from the network. Based on the message type,
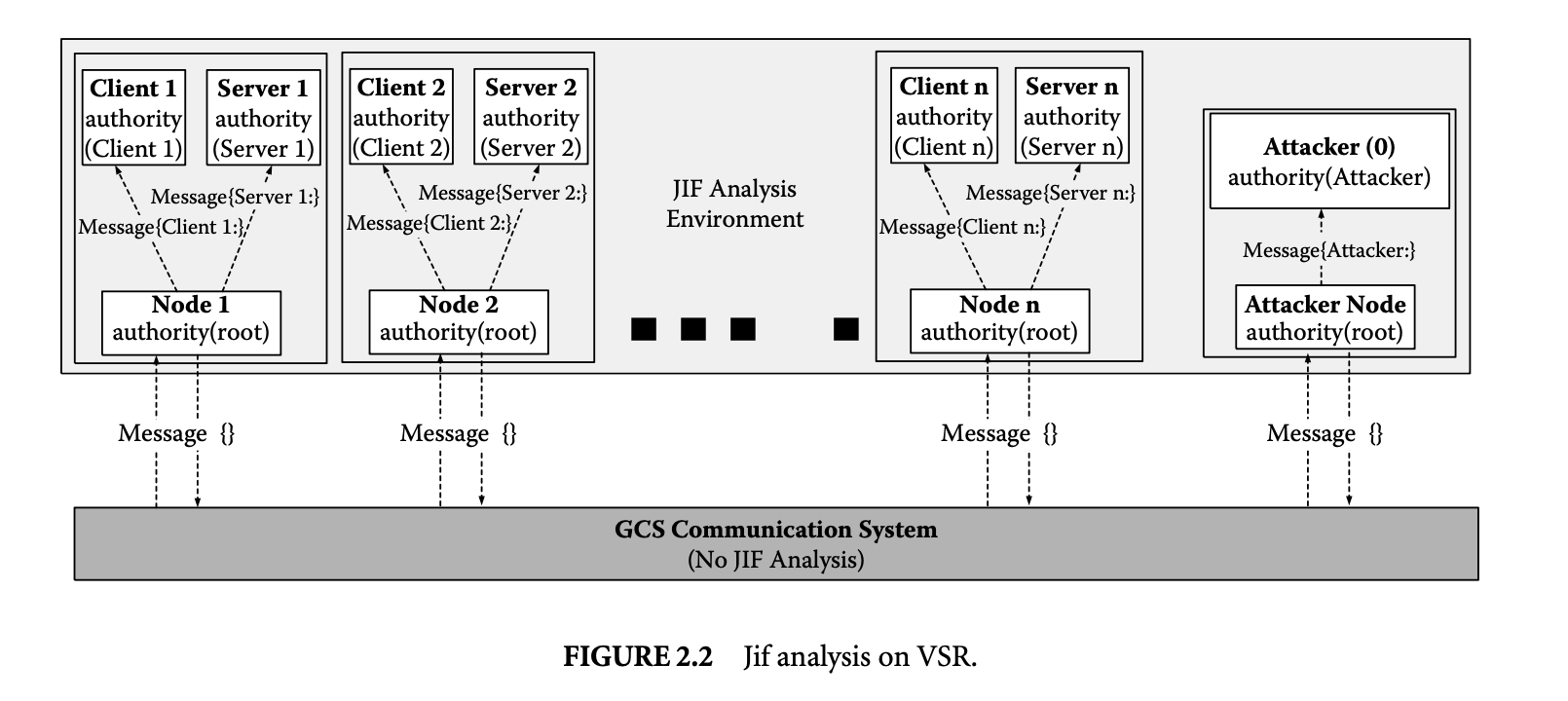
root will appropriately (classify or) declassify the contents of the message and handles them by giving them to either the client or server. Similarly, all outgoing messages from Client/Server to communication network would be properly declassified.
First, the communication interface (Java Ensemble) uses some native methods to contact ensemble-server.9 To do asynchronous communication we use threads in our VSR implementation. Since Jif does not support Java Threads and native methods, Jif analysis cannot be done at this level. Hence, we have to restrict the Jif analysis above the communication layer.10
ensemble-server is a daemon serving group communication.
Because of this separation, we encounter a problem with the Jif analysis even if we want to abstract out the lower GCS layer. Some of the classes (such as the Message class) are common to both upper and lower layers, but they are compiled by two different compilers (Jif and Java) that turn out to have incompatible .class files for the common classes.
Next, let us proceed to do static analysis on the remaining part using the Jif compiler. Consider the Attacker Node (see Figure 2.2). The attacker node (running with root authority) classifies all content going to the principal Attacker with the label-Attacker :. If the attacker has compromised some server, it would get all the valid shares belonging to that server. Hence, all shares of a compromised server output from the communication interface (GCS) go to the attacker node first. Since it is running with root authority and sees that shares are semi-sensitive, it (de)classifies these shares to {Server:}. For these shares to be read by the attacker, the following property should hold: {Server:} {Attacker:}.
However, since the Attacker principal does not actsfor this Server (principal), the above relation does not hold, so the attacker cannot read the shares. The Jif compiler detected this as an error. However, if we add an actsfor relation from Attacker (principal) to this Server (principal) (i.e., Attacker actsfor Server), it could read the shares. In this case, the Jif compiler does not report any error, implying that the information flow from {Server:} to {Attacker:} is valid (since {Server:} {Attacker:} condition holds).
VSR has a threshold property: if the number of shares (or subshares) is more than the threshold, the secret can be reconstituted. This implies that any computation knowing less than the threshold number of shares cannot interfere with any computation that has access to more than this threshold. We need a threshold set noninterference property. This implies that we can at most declassify less than any set of a threshold number of shares. Since such notions are not expressible in Jif, even if mathematically proved as in [58], more powerful dependent-type systems have to be used in the analysis. Since modern type inference is based on explicit constraint generation and solving, it is possible to model the threshold property through constraints, but solving such constraints will have a high complexity. Fundamentally, we have to express the property that any combination of subshares less than the threshold number cannot
interfer (given that the number of subshares available is more than this number); either every case has to be discharged separately or symmetry arguments have to be used. Approaches such as model checking (possibly augmented with symmetry-based techniques) are indicated.
There is also a difficulty in Jif in labeling each array element with different values. In the Client class, there is a function that calculates and returns the shares of a secret. Its skeleton code is as follows:

In line 2, "shares" is an array of type "Share" with a label of [Client:] for both array variable and individual elements of this array. Line 5 calculates different shares for different servers based on ServerIDs and assigns a different label of {Client:ServerServerID[i]} for each of these shares. However, Jif does not allow for different labels for different elements of an array; it only allows a common label for all elements of an array. If this is possible, we should ensure that accessing some array element does not itself leak some information about the index value.
There are currently many other difficulties in using Jif to do analysis such as the need to recode a program in Jif. The basic problem is the (post hoc) analysis after an algorithm has already been designed. What is likely to be more useful11 is an explicit security policy before the code is developed [60] and then use of Jif or a similar language to express and check these properties where possible. McCamant and Ernst [43] argue that Jif-type static analysis is still relatively rare and no "large" programs have yet been ported to Jif or FlowCaml. They instead use a fine-grained dynamic bit-tracking analysis to measure the information revealed during a particular execution.
In the verification area, it is increasingly becoming clear that checking the correctness of finished code is an order of magnitude more difficult than intervening in the early phases of the design.
2.6 Future Work
Current frameworks such as Jif have not been sufficiently developed. We foresee the following evolution:
- The analysis in Section 2.5.1 assumed that typing can reveal interesting properties. This needs to be extended to a more general static analysis that deals with values in addition to types as well as when the language is extended to include arrays and so on. Essentially, the analysis should be able to handle array types with affine index functions. This goes beyond the analysis possible with type analysis.
- Incorporate pointers and heaps in the analysis. Use dataflow analysis on lattices but with complex lattice values (such as regular expressions, etc.) or use shape analysis techniques.
- Integrate static analysis (such as abstract interpretation and compiler dataflow analysis) with model checking to answer questions such as: What is the least/most privilege a variable should have to satisfy some constraint? This may be coupled with techniques such as counterexample guided abstraction refinement [13]. This, however, requires considerable machinery. Consider, for example, a fully developed system such as the SLAM software model checking [3]. It uses counterexample-drivenabstraction of software through "boolean" programs (or abstracted programs) using model creation (c2bp), model checking (bebop), and model refinement (newton). SLAM builds on the OCaml programming language and uses dataflow and pointer analysis, predicate abstraction and symbolic model checking, and tools such as CUDD, a SAT solver, and an SMT theorem prover [3]. Many such analyses have to be developed for static analysis of security properties.
References
[1] Martin Abadi. Secrecy by Typing in Security Protocols. TACS 1997.
[2] Andrew W. Appel and Edward W. Felten. 1999. Proof-carrying authentication. Proceedings of the 6th ACM Conference on Computer and Communications Security, 52-62. New York: ACM Press.
[3] Thomas Ball and Sriram K. Rajamani. 2002. The SLAM project: debugging system software via static analysis. In Proceedings of the 29th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, 1-3.
[4] B. Barak, O. Goldreich, R. Impagliazzo, S. Rudich, A. Sahai, S. Vadhan, and K. Yang. 2001. On the (im)possibility of obfuscating programs. In Advances in cryptology (CRYPTO'01). Vol. 2139 of Lecture notes in computer science, 1-18, New York: Springer.
[5] Jorg Bauer, Ina Schaefer, Tobe Toben, and Bernd Westphal. 2006. Specification and verification of dynamic communication systems. In Proceedings of the Sixth International Conference on Application of Concurrency to System Design, 189-200. Washington, DC: IEEE Computer Society.
[6] D. Elliott Bell and Leonard J. LaPadula. 1973. Secure computer systems: Mathematical foundations. MITRE Corporation.
[7] Matt Bishop. 2002. Computer security: Art and science. Reading, MA: Addison-Wesley.
[8] R. Canetti. 2001. Universally composable security: A new paradigm for cryptographic protocols. 42nd FOCS, 2001. Revised version (2005). Online: http://eprint.iacr.org/2000/067
[9] Bryan M. Cantrill, Michael W. Shapiro, and Adam H. Leventhal. 2004. Dynamic instrumentation of production systems. In Proceedings of the 2004 USENIX Annual Technical Conference.
[10] Hao Chen, David Wagner, and Drew Dean. 2002. Setuid demystified. In Proceedings of the 11th USENIX Security Symposium, 171-90. Berkeley, CA: USENIX Assoc.
[11] David M. Chess and Steve R. White. 2000. An undetectable computer virus. Virus Bulletin Conference.
[12] S. Chong, A. C. Myers, K. Vikram, and L. Zheng. Jif reference manual. http://www.cs.cornell.edu/jif/doc/jif-3.0.0/manual.html.
[13] Edmund M. Clarke, Orna Grumberg, Somesh Jha, Yuan Lu, and Helmut Veith. 2000. Counterexample-guided abstraction refinement. In Proceedings of the 12th International Conference on Computer Aided Verification, 154-69. London: Springer Verlag.
[14] Edmund M. Clarke, Orna Grumberg, and Doron A. Peled. 2000. Model checking. Cambridge, MA: MIT Press.
[15] P. Clarke, J. E. Elien, C. Ellison, M. Fridette, A. Morcos, and R. L. Rivest. 2001. Certificate chain discovery in SPKI? SDSI. J. Comp. Security 9:285-332.
[16] Fred Cohen. 1987. Computer viruses: Theory and experiments. Comp. Security 6, Vol 6(1), pp. 22-35.
[17] Dorothy E. Denning and Peter J. Denning. 1977. Certification of programs for secure information flow. Commun. ACM 20(7):504-13.
[18] D. Dougherty, K. Fisler, and S. Krishnamurthi. 2006. Specifying and reasoning about dynamic access-control policies. International Joint Conference on Automated Reasoning (IJCAR), August 2006.
[19] Dawson Engler, Benjamin Chelf, Andy Chou, and Seth Hallem. Checking system rules using system-specific, programmer-written compiler extensions. In Proceedings of the 4th Symposium on Operating System Design and Implementation, San Diego, CA, October 2000.
[20] P. Feldman. 1987. A practical scheme for non-interactive verifiable secret sharing. In Proceedings of the 28th IEEE Annual Symposium on Foundations of Computer Science, 427-37.
[21] Vinod Ganapathy, Trent Jaeger, and Somesh Jha. 2005. Automatic placement of authorization hooks in the Linux security modules framework. In Proceedings of the 12th ACM Conference on Computer and Communications Security, 330-39. New York: ACM Press.
[22] Vinod Ganapathy, Trent Jaeger, and Somesh Jha. 2006. Retrofitting legacy code for authorization policy enforcement. Proceedings of the 2006 Symposium on Security and Privacy, 214-29. Washington, DC: IEEE Computer Society.
[23] V. Ganapathy, S. Jha, D. Chandler, D. Melski, and D. Vitek. 2003. Buffer overrun detection using linear programming and static analysis. In Proceedings of the 10th ACM Conference on Computer and Communications Security (CCS), 345-54. New York: ACM Press.
[24] Joseph A. Goguen and Jos Meseguer. 1982. Security policies and security models. In Proceedings of the 1982 IEEE Symposium on Security and Privacy, 11-20. Los Alamitos, CA: CS Press.
[25] Mohamed G. Gouda and Alex X. Liu. 2004. Firewall design: Consistency, completeness, and compactness. In Proceedings of the 24th International Conference on Distributed Computing Systems, 320-27. Washington, DC: IEEE Computer Society.
[26] V. H. Gupta and K. Gopinath. 2006. An extended verifiable secret redistribution protocol for archival systems. In International Conference on Availability, Reliability and Security, 100-107. Los Alamitos, CA: IEEE Computer Society.
[27] Joshua D. Guttman, Amy L. Herzog, and John D. Ramsdel. 2003. Information flow in operating Systems: Eager formal methods. WITS2003.
[28] K. W. Hamlen, Greg Morrisett, and F. B. Schneider. 2005. Computability classes for enforcement mechanisms. ACM TOPLAS 28:175-205.
[29] M. A. Harrison, W. L. Ruzzo, and J. D. Ullman. 1976. Protection in operating systems. Commun. ACM 19:461-71.
[30] Mark Hayden and Ohad Rodeh. 2004. Ensemble reference manual. Available online: http://dsl.cs. technion.ac.il/projects/Ensemble/doc/ref.pdf
[31] Trent Jaeger, Reiner Sailer, and Xiaolan Zhang. 2003. Analyzing integrity protection in the SELinux example policy. In Proceedings of the 11th USENIX Security Symposium. USENIX.
[32] Trent Jaeger, Xiaolan Zhang, and Fidel Cacheda. 2003. Policy management using access control spaces. ACM Trans. Inf. Syst. Security. 6(3):327-64.
[33] Sushil Jajodia and Yvo Desmedt. 1997. Redistributing secret shares to new access structures and its applications. Tech. Rep. ISSE TR-97-01, George Mason University.
[34] S. Jha and T. Reps. 2002. Analysis of SPKI/SDSI certificates using model checking. In Proceedings of the 15th IEEE Workshop on Computer Security Foundations, 129. Washington, DC: IEEE Computer Society.
[35] Jif: Java + information flow. <www.cs.cornell.edu/jif/>.
[36] R. B. Keskar and R. Venugopal. 2002. Compiling safe mobile code. In The compiler design handbook. Boca Raton, FL: CRC Press.
[37] M. Koch, L. V. Mancini, and F. Parisi-Presicce. 2002. Decidability of safety in graph-based models for access control. In Proceedings of the 7th European Symposium on Research in Computer Security, 229-43. London: Springer-Verlag.
[38] Butler W. Lampson. 1973. A note on the confinement problem. Commun. ACM 16(10):613-15.
[39] Felix Lazebnik. 1996. On systems of linear Diophantine equations. Math. Mag. 69(4).
[40] N. Li, B. N. Grosof, and J. Feigenbaum. 2003. Delegation logic: A logic-based approach to distributed authorization. ACM Trans. Inf. Syst. Security 6:128-171.
[41] Ninghui Li, John C. Mitchell, and William H. Winsborough. 2005. Beyond proof-of-compliance: Security analysis in trust management. J. ACM 52:474-514.
[42] Ninghui Li and Mahesh V. Tripunitara. 2005. Safety in discretionary access control. In Proceedings of the 2005 IEEE Symposium on Security and Privacy, 96-109. Washington, DC: IEEE Computer Society.
[43] Stephen McCamant and Michael D. Ernst. 2006. Quantitative information-flow tracking for C and related languages. MIT Computer Science and Artificial Intelligence Laboratory Tech. Rep. MIT-CSAIL-TB-2006-076, Cambridge, MA.
[44] Steven McCanne and Van Jacobson. 1993. The BSD packet filter: A new architecture for user-level packet capture. In Proceedings of the Winter Usenix Technical Conference, 259-69.
[45] Andrew C. Meyers. 1999. Mostly-static decentralized information flow control. MIT Laboratory for Computer Science, Cambridge, MA.
[46] George C. Necula, Scott McPeak, and Westley Weimer. 2002. CCured: Type-safe retrofitting of legacy code. In Annual Symposium on Principles of Programming Languages, 128-39. New York: ACM Press.
[47] Seth Nielson, Seth J. Fogarty, and Dan S. Wallach. 2004. Attacks on Local Searching Tools. Tech. Rep. TR04-445, Department of Computer Science, Rice University, Honston, TX.
[48] T. P. Pedersen. 1991. Non-interactive and information theoretic secure verifiable secret sharing. In Proceedings of CRYPTO 1991, the 11th Annual International Cryptology Conference, 129-40. London: Springer Verlag.
[49] Francois Pottier and Vincent Simonet. 2003. Information flow inference for ML. ACM Transac. Programming Languages Syst. 25(1):117-58.
[50] J. Rao, P. Rohatgi, H. Scherzer, and S. Tinguely. 2002. Partitioning attacks: Or how to rapidly clone some GSM cards. In Proceedings of the 2002 IEEE Symposium on Security and Privacy, 31. Washington, DC: IEEE Computer Society.
[51] A. Shamir. 1979. How to share a secret. Commun. ACM, 22(11):612-13.
[52] Geoffrey Smith and Dennis M. Volpano. 1998. Secure information flow in a multi-threaded imperative language. In Proceedings of the 25th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, 355-64. New York: ACM Press.
[53] Ken Thompson. 1984. Reflections on trusting trust. Commun. ACM, 27(8): 761-63.
[54] M. Y. Vardi. 1982. The complexity of relational query languages (extended abstract). In Proceedings of the 14th Annual Symposium on the Theory of Computing, 137-46. New York: ACM Press.
[55] Dennis M. Volpano, Cynthia E. Irvine, and Geoffrey Smith. 1996. A sound type system for secure flow analysis. J. Comput. Security 4(2/3):167-88.
[56] D. Wagner, J. Foster, E. Brewer, and A. Aiken. 2000. A first step towards automated detection of buffer overrun vulnerabilities. In Symposium on Network and Distributed Systems Security (NDSS00), February 2000, San Diego, CA.
[57] Wlikipedia. Trusted Computer System evaluation criteria. http://en.wikipedia.org/wiki/Trusted_Computer_System_Evaluation.
[58] Theodore M. Wong, Chenxi Wang, and Jeannette M. Wing. 2002. Verifiable secret redistribution for archival systems. In Proceedings of the First IEEE Security in Storage Workshop, 94. Washington, DC: IEEE Computer Society.
[59] Steve Zdancewic and Andrew C. Myers. 2001. Robust declassification. In Proceedings of the 2001 IEEE Computer Security Foundations Workshop.
[60] Steve Zdancewic, Lantian Zheng, Nathaniel Nystrom, and Andrew C. Myers. 2001. Untrusted hosts and confidentiality: Secure program partitioning. In ACM Symposium on Operating Systems Principles. New York: ACM Press.